Mnoho lidí si neumí představit, co to vlastně ta umělá inteligence je. A jelikož marketing lidi solidně masíruje tímto pojmem, tak se tento pojem stává velice nadhodnocený. Ale ve skutečnosti to není zase taková věda jak se zdá. V tomto článku se budu snažit vysvětlit umělou inteligenci jednoduchým způsobem.
Můj výklad se bude opírat o video dostupné na https://www.youtube.com/watch?v=vDDjtwQDw2k. Toto video jsem vybral, neboť je zde použita technologie, která mi je blízká a líbí se mi celkový koncept, pomocí kterého autor umělou inteligenci vysvětluje. Navíc zde nejsou použity knihovny, což celou problematiku dost zjednodušuje. Nečekám, že se někdo bude dívat na nic neříkající 4 hodinové video, proto se budu snažit obsah videa rozebrat zde.
Co se týče obsahu videa, hlavním tématem je tvorba aplikace, která má za úkol „hádat“, jaký obrázek uživatel nakreslil. Pro zjednodušení je použito pouze 8 obrázků: auto, ryba, dům, strom, kolo, kytara, tužka a hodiny. Uživatel nakreslí jednu ze zmíněných věcí (jakýmkoliv způsobem) a aplikace řekne, co nakreslil.
Příprava dat
Autor vytvořil aplikaci, kterou vystavil veřejně tak, aby kdokoliv mohl aplikaci používat. Během této doby bylo posbíráno cca 500 vstupů, kde jednotliví uživatelé nakreslili zmíněných 8 obrázků a jejich data byla uložena. Autor videa tyto data vzal a začal provádět data-cleaning. Tzn. že buďto manuálně nebo programově se snažil eleminovat obrázky, které jsou fiktivní (např. když nějaký uživatel místo auta nakreslil pohlavní orgán). Dále musel autor obrázky tzv. normovat, kde se např. hodilo mít obrázky „přibližně stejně velké“. Jeden uživatel mohl nakreslit obří rybu a další mohl nakreslit rybu maličkou. Tento jev by mohl zkreslovat při nadcházejích operacích, proto je zde užitečná funkce zoom. Výsledná sada obrázků mohla vypadat např. takto:

Identifikace vlastností
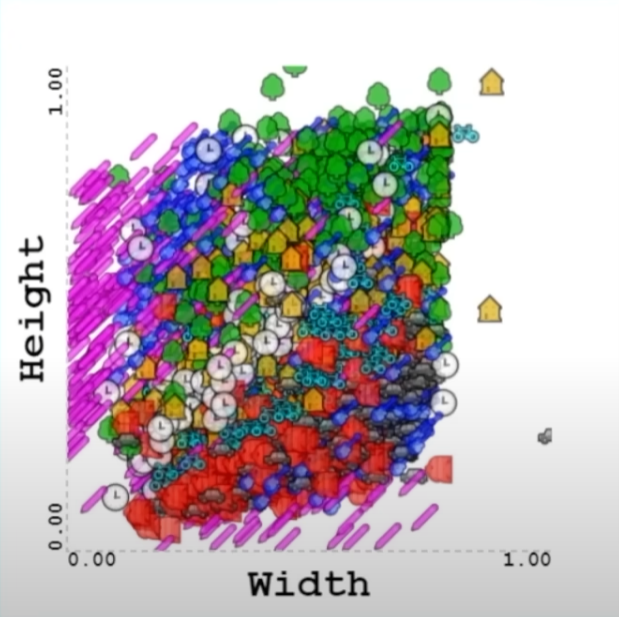
Nyní to začíná být trochu zajímavější. V této sekci se řeší otázka: co můžeme na obrázku pozorovat? Ať už se jedná o metriky, tvar, vzhled apod. Je nutno podotknout, že uživatelé kreslili obrázky na „plátno“, které má osu X a Y. Uživatel když kreslil tak „zanechával“ buďto bod (např. kliknutí myší) nebo křivku (např. podržení myši, táhnutí a uvolnění myši). To je vlastně první metrika: počet bodů a počet křivek u jednotlivých obrázků, které můžeme pozorovat. Další metrikou může být šířka a výška obrázku (lidé mají ve zvyku kreslit tužku jako „svislou čáru“). Existuje celá řada těchto metrik, které se dají pozorovat, např. poměr stran, procento výplně obrazců apod. Je možné se vymyslet mnoho vlastních metrik. Metriky následně můžete dát do grafu a pozorovat je. Zde je např. vyobrazení šířky a výšky obrázků:
Klasifikátor
Klasifikátor je označení pro rozhodovací mechanismus, který bude „hádat“ výsledek. V tomto případě autor volil klasifikátor KNN – nearest neightbour, který vyhledá určitý počet K sousedů dané metriky. To je možné si představit tak, že pokud nakreslím nějaký obrázek, tak na základě nějaké metriky (v tomto případě výška a šířka), KNN vyhledá např. 10 nejbližších sousedů, takto:
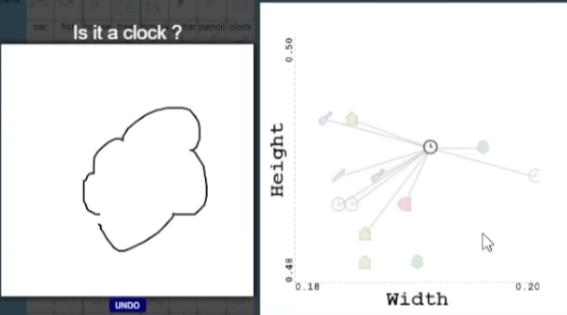
Poté vyhodnotí, že většina sousedů je typu „hodiny“ a tudíž výstupem aplikace jsou hodiny.
Trénovací a testovací model
Je zde otázkou jak určit správný počet vyhodnocených sousedů KNN klasifikátoru. K tomu nám může posloužit testovací model. Testovací model se dá sestavit následovně. Nejprve je potřeba vzít všechny položky trénovacího modelu (data, na kterých byl proveden data-cleaning, normalizace apod.) a přiřadit jim správný výsledek (např. pokud je na obrázku ryba, tak výsledek je ryba). Potom následuje samotné testovaní, kdy pro každou položku testovacího modelu se spustí aplikace a vyhodnotí výsledek. Tzn. že se vezme nějaký obrázek např. s rybou, spustí se aplikace, vyhodnotí se výsledek, který bude určen jako ryba, a vyhodnotí se test. Pokud obrázek odpovídá výsledku, tak byl ten pozitivní a v opačném případě negativní. V závěru se vezme počet pozitivních testů a vydělí se celkovým počtem položek. Např. 500 (počet pozitivně určených položek) / 2000 (celkový počet položek) je ve výsledku 25%. Toto procento udává úspěšnost modelu. Samozřejmě je snahou mít úspěšnost co nejvyšší a tím zajistit i co největší přesnost modelu. V tomto případě, když se zpřesňuje dle KNN klasifikátoru, tak můžeme nastavit vždy jinou hodnotu pro počet sousedů, následně spustit test a pozorovat, jak se změnila úspěšnost modelu. Např. když pro K=3 byla úspěšnost 25% a pro K=10 byla úspěšnost 50%, tak K=10 je výhodnější. Nejlepší volbou je udělat test pro všechny možné hodnoty např. K=<1;2000> a vybrat nejvyšší úspěšnost.
Neuronová síť
Vlastnosti a klasifikátor byly vysvětleny a nyní je potřeba těmto položkám přiřadit váhy. Máme různé vlastnosti (výška a šířka, bod a křivka, poměr stran, procento výplně obrazců). Snahou je, aby se aplikace rozhodovala na základě více vlastností zároveň. Podle jednoduchého vzorce x₁·w₁, kde x₁ je vstup (např. výška kresleného obrázku) a w₁ je váha (pozorovaná vlastnost), přiřazujeme jednotlivým vlastnostem jejich váhu. To můžeme provést manuálně nebo programově.
Výsledkem vzorce je číslo z intervalu <-1; 1>, kde hodnota blížící se jedničce „aktivuje“ daný neuron a hodnota blížící se mínus jedničce jej „deaktivuje“. V tomto jednoduchém případě neuron představuje samotný výsledek (hádaný obrázek). Například když uživatel nakreslí svislou čáru → obrázek je vysoký → vysoký vstup x₁ → váha vede k výsledku „tužka je vysoká“ → aplikace určí výsledek: tužka.
Podobně jako u klasifikátoru se v trénovacím modelu váhy určují na základě učení. To znamená, že se zadají počáteční váhy, spustí se trénovací model a výsledkem je úspěšnost modelu. Celý proces se opakuje, dokud se nepodaří dosáhnout co nejvyšší úspěšnosti. Neuronová síť může být reprezentována takto:
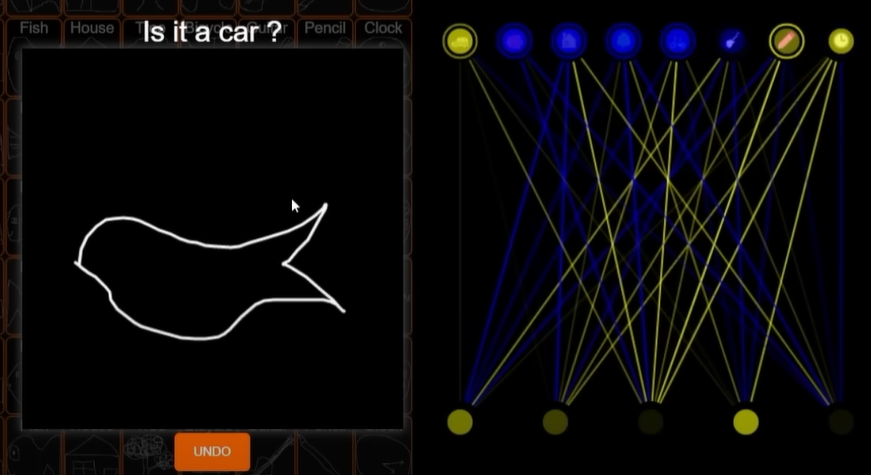
V levé části je vstup, kde se autor pravděpodobně snažil nakreslit ptáčka. Napravo je schéma neuronové sítě, kde se v dolní části nachází vlastnosti/parametry (5×) a v horní části neurony/hádané obrázky (8×). Žlutá barva symbolizuje aktivaci neuronu (hodnota blížící se jedničce) a modrá barva symbolizuje deaktivaci neuronu (hodnota blížící se minus jedničce). Aplikace vyhodnotila výsledek jako auto. To je však nesprávně, protože test byl proveden na modelu s úspěšností 33,28 % a ptáček je mimo rámec této aplikace.
LLM
A to je všechno, o tom to celé je. Jako doplnění ještě rozeberu LLM. LLM je označení pro „umělou inteligenci“, kam vás všichni posílají s nějakým dotazem, když si neví rady. Např. dej to do umělé inteligence, vyhledej to umělou inteligencí, vygeneruj si to umělou inteligencí apod.
LLM – large language model, neboli velký jazykový model (ano, to je ten správný název, který by měli všichni používat), je model zabývající se porozuměním lidskému jazyku. Fór je v tom, že on lidskému jazyku vůbec nerozumí, pouze hádá správný výsledek. Nemůžu srovnávat LLM, jehož základy vznikaly desítky let a na jehož trénování se spouštějí clustery po dobu i několika měsíců, s malou aplikací, kterou jsem v tomto článku popsal. Nicméně princip je stejný.
LLM, jak už napovídá jeho název, využívá velké množství trénovacích dat (knihy, publikace, internet), na kterých se učí predikovat následující slovo/token (LLM pracuje s tokeny, což vždy nemusí být slovo). Takže když uživatel napíše do vstupu (LLM vstup bývá otázka): „Kočka seděla na“, tak výstupem bude (LLM výstup bývá odpověď): „stromě“. Proč? Protože je to statisticky nejčetnější výskyt na základě trénovacích dat.
A teď k tomu přihoďte vlastnosti/parametry (nebudu udávat příklady, protože LLM často využívá matematicko-statistické parametry, které se týkají především tokenů) s danými váhami a vznikne vám model neuronové sítě (např. ChatGPT).
Pro zajímavost: LLM dnes disponují až miliardami parametrů/vlastností. Nicméně jde tak trochu o kolizi názvů. V LLM parametry/vlastnosti představují váhy (nebo biasy), což jsou dá se říct spoje (body) mezi vstupem (parametr z popisované ukázky) a výstupem (výsledný obrázek z ukázky). Těchto bodů může být mezi vstupem a výstupem více. V LLM se mohou vyskytovat desítky vstupů, které potom mohou vést dál k vahám a jejich výsledkům. Celkově to pak může tvořit komplexní neuronovou síť až o miliardě prvcích, která je reprezentována vektorovou databází.